Latent Diffusion Model (LDM)
논문
Diffusion Model (DDPM)을 먼저 습득하세요!
Latent에 Diffusion을 적용한다 (원래는 픽셀에 직접 적용했었다)
논문의 의의 (Contributions)
- pixel-level에 diffusion을 적용하는 것이 아니라 압축된 latent에 diffusion을 적용해서 더 고차원의 데이터를 자세하고 정확하게 생성할 수 있다.
- 기존 pixel-level diffusion에 비해 컴퓨팅 자원을 효율적으로 사용할 수 있다.
그러면서도 여러 task에서 사용 가능하다. - reconstruction과 generation ability 사이의 균형을 예민하게 조정하지 않고 훈련할 수 있다. (주로 GAN이 이러한 문제에서 자유롭지 않다)
- 1024x1024 해상도가 넘는 고화질의 이미지를 렌더할 수 있다
- 멀티 모달 학습을 위한 conditioning 매커니즘도 적용하여 제안했다.
- 깃허브에 코드 올렸으니깐 쓰세유~
간단하게, 원래 전체 이미지에서 각 픽셀 단위로 디퓨젼과 denoise를 적용하던 것을, 이제 latent에서 해서 계산량을 줄이겠다!!
모델 구조
LDM은 latent로 압축하는 압축 단계와 생성 단계를 명시적으로 나누었다는 것이 기존 DM(Diffusion Model (DDPM))과의 가장 큰 차이점이 되겠다.
Auto Encoder와 같은 모델을 학습해 의미있는 latent를 만들고, latent에서 generation을 학습하는 형식으로 이루어진다.
또한 conditioning을 추가할 수 있는데, 이것 때문에 text-to-image 같은 multi-modal을 만들 수 있다.
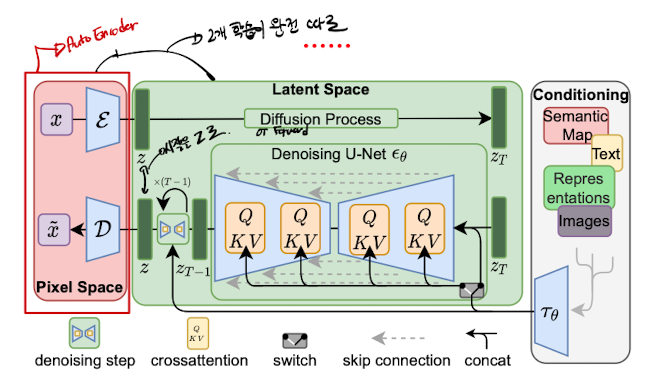
1. Latent로 압축 단계
perceptual loss와 patch-based adversarial objective를 조합한 Auto Encoder를 사용하여 전체 이미지를 의미 있는 latent로 압축한다.
Auto Encoder에서 latent의 분산(variance)가 너무 높아지면 안 좋다.
이러한 High-variance latent space는 주어진 인풋 데이터에서 중요한 feature를 일관되게 포착하지 못했다는 것을 의미한다.
이를 해결하기 위해 두 가지 방법 중 하나를 쓸 수 있다. (각 방법에 따른 실험 결과는 논문에서 이후에 나온다)
- KL Regularization
- VQ regularization
두 번째인 VQ regularization을 사용하는 경우에는 디코더에 quantization layer를 두는 방식으로 구현한다.
VAE 같은 기존 모델과 비교해보면, latent가 그냥 1D array 형태로 표현된다. 반면에 Diffusion Model에서는 Latent가 2차원이 된다 (노이즈가 낀 이미지니깐)
그래서 이미지의 inductive bias를 챙길 수 있는 것이다.
다시 말하자면, 위 그림의 빨간 부분을 보자. 빨간 부분만 똑 때어놓고 보면 영락없는 Auto Encoder이다.
여기서 모든 Auto Encoder의 중간에 있는 latent
2. LDM
Diffusion Model (DDPM)에서 언급한 내용인데, 다시 논문에 맞게 정리한 loss는 아래와 같다.
이런 loss를 보면, 각 step마다 적용되는 denoising autoencoder
LDM에서는 DM과는 다르게 앞서 latent로 압축이 된 latent에 대해 diffusion 및 reverse process를 수행한다.
이렇게 latent에 바로 디퓨젼을 하면 두 가지 좋은 점이 있는데,
- 너무 세부적인 디테일이 아닌 의미적으로 중요한 데이터에 집중할 수 있고
- 낮은 차원에서 연산하기 때문에 컴퓨팅 자원이 적게 소요된다.
이렇게 latent에 디퓨젼을 바로 적용하는 것을 loss로 표현하면,
샘플링을 인코더의 결과물인
이미지의 inductive bias를 유지하기 위하여, 디노이징을 위한 모델
그리고 CNN 구조도 포함되며 cross-attention도 사용한다....는데 도대체 어떻게 생긴거냐?
뒤에서 더욱 자세한 구조를 알아보겠다.
3. Conditioning
text-to-image등 condition generation을 하기 위한 방법을 설명한다.
예를 들어서, 프롬프트를 넣고 이미지를 생성하는 방식은 "이 프롬프트"라는 조건 하에서 디노이즈를 수행하여, 조건에 알맞은 확률 분포를 생성하는 것이다.
기본적으로 텍스트든, 다른 이미지, 등등등 여러 가지를
이렇게 임베딩된 condition을 UNet (디노이저의 backbone)의 cross attention으로 넣어준다. 구체적으로 Key와 Value 값에 넣어주는 것이다.
그래서 아래와 같이 UNet 안의 cross attention이 이루어진다. (그니깐 self-attention이 아니죠 ㅎ)
이렇게 되면 아래와 같이 Loss가 바뀐다.
이 loss를 사용하면
디노이즈 모델은 정확히 어떻게 생긴것일까?
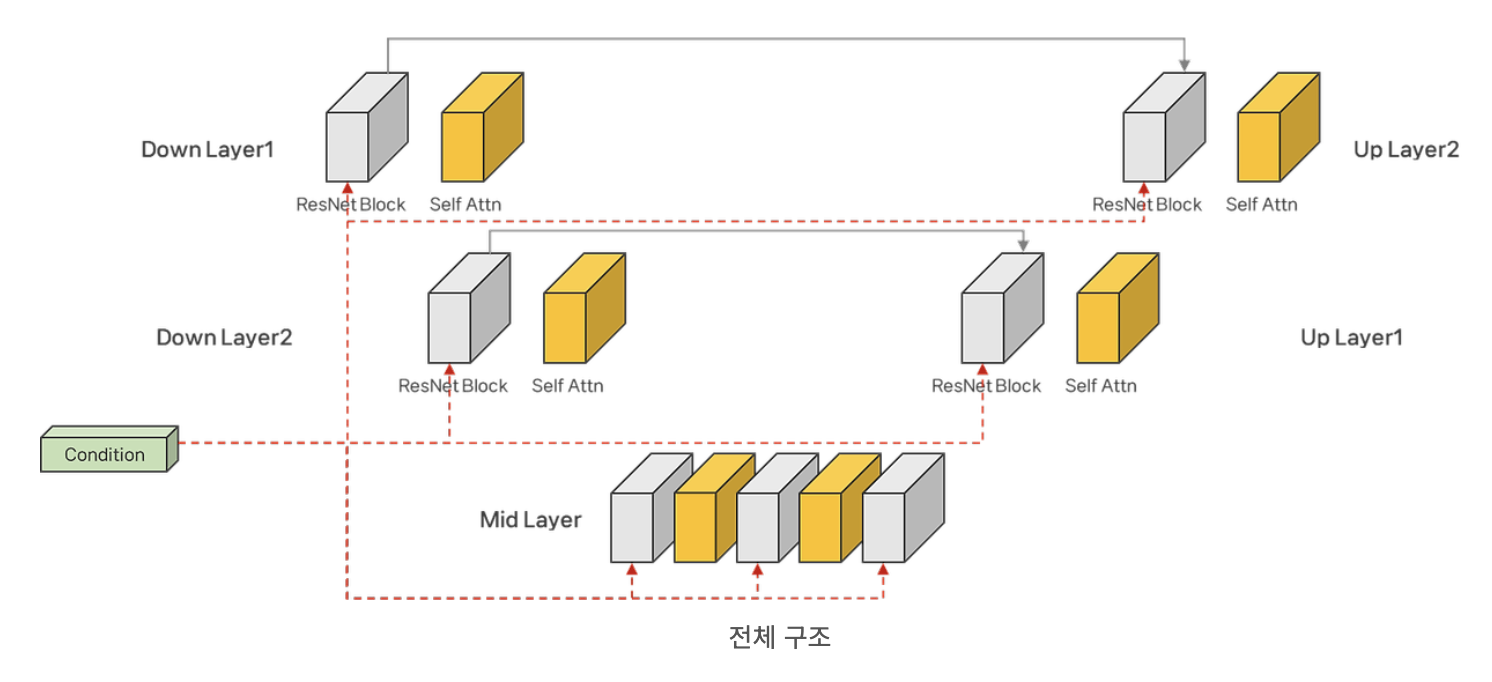
위와 같이 ResNet 블록과 Attention 블록이 혼합된채로 존재한다. 출처
근데 왜 condition이 attention 블록이 아니라 ResNet 블록에 들어가게 되는 것인지는 모르겠다...?
(QKV로 cross attention 한다며 왜 self attention이야?)
마지막으로 전체 구조를 보며 전체 LDM의 구조를 복기해본다...
(skip connection과 같은 부분은 UNet의 구조였다!)
실험
실험 부분에서 중요한 점들을 꼽아보자면 다음과 같다. (자세한 것은 본 논문 참고하세유)
- 원본 이미지를 latent로 압축하는 정도에 따라, 너무 많이 압축하면 성능이 떨어지고 조금밖에 압축하지 않으면 연산을 너무 많이 해야한다. 4~16배 정도 압축하는 것이 적절하다고 한다.
에 따라서 여러 task를 수행할 수 있다. text-to-image 생성, Super Resolution (화질 상승), Inpainting 등등을 수행할 수 있다.